深拷贝与浅拷贝问题的记录
Table of Contents
深浅拷贝的问题记录
原代码 👇
def parse_more_rank(self, response):
items = response.meta.get("items")
url_list = response.xpath('//a[@class="figure_pic"]/@href').getall()
ranking_list = response.xpath('//a[@class="figure_pic"]/span/text()').getall()
title_list = response.xpath('//a[@class="figure_pic"]/following-sibling::strong/a/text()').getall()
cover_id_list = [u.split('cover/')[1].split(".")[0] for u in url_list]
for url,ranking,title,cover_id in zip(url_list,ranking_list,title_list,cover_id_list):
items["ranking"] = ranking
items["title"] = title
items["cover_id"] = cover_id
yield scrapy.Request(url, callback=self.parse_detail,
meta={"items": items}, dont_filter=True)
程序运行到for循环都是没有问题的。到一个解析回调self.parse_detail的时候就出现了问题。存储的所有数据都是最后一条。(因为不同的排行榜中有相同的作品,所以没有过滤重复请求。)
最后排查是传递meta传递items的时候的问题,没有使用深拷贝,导致最后解析回调的时候都是同一个对象。
更改后
yield scrapy.Request(url, callback=self.parse_detail,
meta=copy.deepcopy({"items": items}), dont_filter=True)
python赋值、深、浅拷贝
参考:
直接赋值: 其实就是对象的引用(别名)。
浅拷贝(copy): 拷贝父对象,不会拷贝对象的内部的子对象。
深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
2022-08-02更新
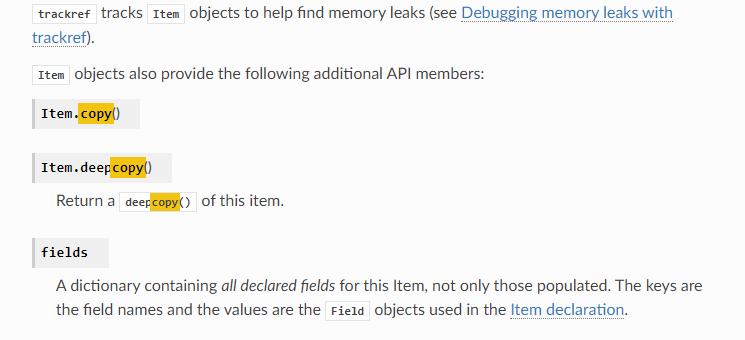
在scrapy文档中看到了关于item拷贝的API
yield scrapy.Request(url=self.info_url.format(info_id), callback=self.parse_info,
meta={"item": item.deepcopy()}, dont_filter=True)
直接使用item.deepcopy()即可。